
W skrócie:
– Plik robots.txt to zwyczajny plik tekstowy, który stanowi zbiór instrukcji dla wszystkich robotów odwiedzających naszą stronę
– Aby plik został odnaleziony przez roboty, musi być umieszczony w katalogu głównym najwyższego poziomu
– W pliku robots.txt rozróżniana jest wielkość liter, dlatego też musi on mieć nazwę „robots.txt” (a nie ROBOTS.txt, robots.TXT itd.)
– Plik robots.txt jest jedynie sugestią – nie ma on mocy egzekwowania, gdzie roboty mogą wchodzić, a nie mogą. Oznacza to, że o ile roboty Google najpewniej za nim podążą, o tyle złośliwe spamboty najpewniej go zignorują.
– Plik /robots.txt jest publicznie dostępny: wystarczy dodać /robots.txt do końca dowolnej domeny głównej, aby zobaczyć dyrektywy allow i disallow. Oznacza to, że każdy może zobaczyć, jakie strony chcesz zaindeksować, jakich nie chcesz oraz gdzie znajduje się Twoja mapa witryny. Nie używaj tego pliku do ukrywania prywatnych informacji użytkowników.
– Każda subdomena na domenie głównej używa oddzielnych plików robots.txt – oznacza to, że zarówno jeśli używasz blog.domena.pl oraz domena.pl – powinny one mieć swoje oddzielne i własne pliki robots.txt (pod adresami blog.domena.pl/robots.txt i domena.pl/robots.txt)
– Dobrze jest w pliku robots.txt umieścić plik z mapą witryny, aby roboty Google sprawniej poruszały się po naszej stronie i indeksowały potrzebną treść.
Plik robots.txt – co to jest?
Plik robots.txt to zbiór instrukcji dla wszystkich robotów odwiedzających naszą stronę, w tym robotów Google, występujący na serwerze jako zwyczajny plik tekstowy. Plik ten występuje w większości stron internetowych, jakie odwiedzasz.
Plik robots.txt jest zwykłym plikiem tekstowym, niezawierającym żadnego kodu HTML (stąd rozszerzenie .txt), który możemy otworzyć i edytować nawet w notatniku. Informuje on roboty indeksujące (ale nie tylko indeksujące!), które zakamarki naszej strony mają odwiedzać, a które lepiej omijać.
Plik robots.txt jest hostowany na serwerze internetowym w katalogu głównym strony. Najczęściej zawiera także adres mapy witryny w formacie xml.
To, co musimy o nim wiedzieć na tym etapie to fakt, iż po pierwsze – jest to zawsze jeden plik, po drugie zawartość pliku robots.txt, pomimo, iż nie jest napisana żadnym językiem programistycznym, musi być sformułowana w odpowiedni sposób za pomocą komend znanych robotom, które opiszemy w późniejszym rozdziale. W przeciwnym razie, roboty nie będą w stanie podążyć za sugestiami pliku.
Chociaż robots.txt zawiera instrukcje dla wszystkich algorytmów odwiedzających i skanujących naszą witrynę, nie ma mocy egzekwowania tych instrukcji – a to znaczy, że jest drogowskazem, wskazówką udzielaną robotom i nie ma żadnej mocy sprawczej nad tym, co faktycznie zrobią niektóre automaty.
Dlaczego używamy pliku robots.txt?
Osoba początkująca w SEO mogłaby zapytać – a po co właściwie nam ten plik robots.txt? Dlaczego chcemy wykluczyć część adresów URL naszej strony, skoro właśnie powinno nam zależeć na tym, aby jak najwięcej ich się zaindeksowało, czym potencjalnie zwiększymy widoczność naszej witryny?
Otóż niektóre strony, nawet jeśli chcielibyśmy, żeby prezentowały jakąkolwiek wartość dla Google’a, będą zupełnie mu niepotrzebne. Przykład – w sklepie internetowym na pewno taką stroną będzie podstrona „Koszyk”, „Realizacja Zamówienia” czy panel administracyjny, do którego dostęp powinniśmy mieć tylko my.
Plikiem robots.txt chcemy dać znać robotom, na indeksowanie których podstron nie warto tracić czasu, dzięki temu optymalizujemy nasz crawl budget.

Dodatkowo, jeśli mamy opcję wyszukiwania produktów w naszym e-commerce, to musimy wiedzieć, iż jeśli nie wykluczymy odpowiednio skonstruowaną regułą w pliku robots.txt adresów, jakie tworzą się w wyniku przeprowadzenia procesu wyszukiwania na stronie (każde wyszukiwanie pojedynczego hasła to oddzielny URL), tak naprawdę możemy stworzyć tysiące różnych, nowych adresów URL, których nie chcesz indeksować, bo nie będą miały one żadnej unikalnej wartości dla Google.
Role i adres URL pliku robots
Do czego służy plik robots?
Rolą robots.txt jest informowanie wszystkich crawlerów, w tym robota Google, których części naszego serwisu nie chcemy, aby ów roboty odwiedzały. Tym samym poprzez dodanie odpowiednich wytycznych w pliku robots txt, dajemy do zrozumienia w szczególności robotowi Google, czego nie chcemy indeksować w wyszukiwarce.
Innymi słowy, pełni on rolę głównie informacyjną dla algorytmów indeksujących naszą stronę o tym, które strony ma omijać. Roboty Google, na których najbardziej nam zależy, regularnie odwiedzają właśnie robots.txt.

Krótka notka: „Crawler” (czasami nazywany również „robotem” ) to ogólny termin dla każdego programu, który służy w internecie do automatycznego odkrywania i skanowania stron internetowych poprzez śledzenie linków z jednej strony do drugiej. Główny crawler Google nazywa się Googlebot, czyli po prostu robot Google.
Dlaczego zaznaczyliśmy, że pełni on rolę informacyjną? Ano dlatego, że plik ten nie blokuje w żaden sposób dostępu robotom ani innym użytkownikom do stron wykluczonych – jedynie informuje on o tym, czego nie chcemy, żeby odwiedzały. To, czy roboty za nim podążą i ominą szereg adresów URL wykluczonych w pliku, zależy tylko od działania ów robotów.
W praktyce wygląda to tak, iż za pomocą pliku robots.txt możemy zarządzać ruchem robotów indeksujących, pochodzących od Google – cała reszta jednak może za nimi w ogóle nie podążać.
Adres URL pliku robots.txt
Adres URL, pod jakim znajdziesz ów plik w praktycznie każdej strony to:
adres.com/robots.txt – na przykładzie https://digitix.pl/robots.txt
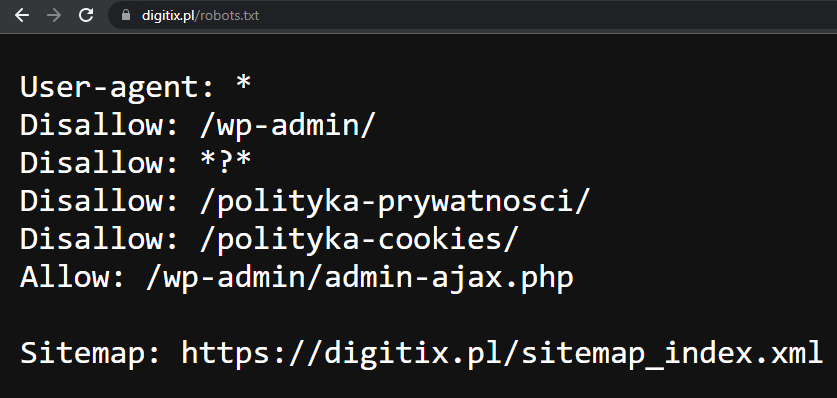
Możesz dodać „/robots.txt” do praktycznie każdej domeny w internecie i sprawdzić tym samym, jakie każda strona www przekazuje robotom wyszukiwarek informacje.
Znaczenie pliku robots dla złośliwych botów
Pliki robots.txt są głównie przeznaczone do informowania tzw. „dobrych” botów, takich jak crawlery internetowe, ponieważ jak już wspomnieliśmy wyżej – „złośliwe boty” prawdopodobnie nie będą przestrzegać instrukcji. Czym są właściwie złośliwe boty?
Najczęściej to spam boty, które w przypadku stron internetowych zalewają formularze kontaktowe lub komentarze pod artykułami ogromną ilością przesłanych danych, zawierających fałszywe informacje lub linki do spamerskich witryn. Stąd powstało m. in. zabezpieczenie CAPTCHA.
Mapa witryny w pliku robots.txt
Mapa witryny to plik zawierający listę wszystkich stron w witrynie, które chcesz, aby roboty odkryły i uzyskały do nich dostęp. Zaleca się, aby plik robots zawierał do niej adres URL. Dlaczego?
Możesz chcieć, aby wyszukiwarki miały dostęp do wszystkich Twoich wpisów na blogu, tak, aby by pojawiły się one w wynikach wyszukiwania jak najszybciej.
Możesz jednak nie chcieć, aby miały dostęp do stron z poszczególnymi tagami, ponieważ mogą one nie być dobrymi stronami docelowymi i dlatego nie powinny być uwzględniane w wynikach wyszukiwania.

Przejrzysta mapa witryny w formacie XML może również zawierać dodatkowe informacje o każdym adresie URL, w formie meta danych. I podobnie jak plik robots, jest dzisiaj konieczna do tego, abyśmy mieli pewność, że roboty indeksujące wyszukiwarek mogą odkryć wszystkie nasze strony, ale także, aby pomóc im zrozumieć znaczenie tych stron – co jest wpisem. co produktem, i tak dalej.
Sprawdzenie pliku robots.txt za pomocą Google Search Console
W najpopularniejszym i bezpłatnym narzędziu Google służącym do monitorowania pozycji naszej witryny w wynikach wyszukiwania, mamy wbudowany tester pliku robots txt.
Jeśli więc mamy naszą witrynę zweryfikowaną w Google Search Console (jeżeli nie – musimy czym prędzej to zrobić), możemy łatwo sprawdzić, czy ustawienia naszego pliku robots.txt pozwalają znaleźć dany adres URL. Przejdziesz do niej klikając TUTAJ.

Wpisując po hackslashu określoną ścieżkę adresu URL oraz klikając przycisk „TEST” dowiemy się, czy poszczególny adres naszej witryny jest dozwolony czy też zablokowany przez robots.txt
Tworzenie pliku robots.txt dla całej witryny
Aby stworzyć plik robots.txt, wystarczy, że utworzymy dokument notatnika w formacie UTF-8. Jeśli jak większość użytkowników używasz Windowsa, możesz wybrać format kodowania pliku przy opcji „Zapisz jako…”

Musimy tu napomnieć, iż istnieje wiele automatycznych i darmowych narzędzi do tego, aby pomóc Ci stworzyć plik robots.txt. Warto z nich skorzystać, jeśli na przykład operujesz na popularnym CMS WordPress, to wtyczka Rank Math SEO pomoże Ci wypełnić dane odpowiednio.
Jeśli jednak jesteś zdecydowany zrobisz to ręcznie lub chcesz dokładnie zrozumieć wszystkie instrukcje, jakie znajdują się w naszym owym mało tajemniczym pliku, znajdziesz je poniżej.
Instrukcje pliku robots.txt
W naszym pliku możemy zaimplementować następującej instrukcje:
User-agent: określa robota, do jakiego się zwracamy. Przykładowo Googlebot Allow oznacza, iż dostęp do strony będzie zablokowany dla wszystkich robotów, poza robotem Google.
Allow: oznacza pozwolenie na odwiedzanie witryny. Polecenie mówi Googlebotowi, że może uzyskać on dostęp do strony lub podfolderu, mimo że jego strona nadrzędna lub podfolder mogą być niedozwolone.
Disallow: oznacza brak pozwolenia na odwiedzacie i jakiekolwiek indeksowania URL.
Crawl-delay: Ile sekund powinien odczekać crawler przed załadowaniem i indeksowaniem zawartości strony.
Sitemap: Służy do wywołania lokalizacji wszelkich sitemap XML powiązanych z tym adresem URL. To polecenie jest obsługiwane tylko przez Google, Ask, Bing i Yahoo.
Blokada całej strony
User-agent: *
Disallow: /Użycie tej składni w pliku robots.txt mówi wszystkim robotom internetowym, aby nie indeksowały żadnych stron w naszej witrynie, w tym strony głównej. „User-agent” to określenie robota, do jakiego się zwracamy, komenda „Disallow” znaczy w praktyce po prostu zabronienie robotom dostępu.
Blokada pojedynczej strony
Chcesz zablokować pojedynczą stronę? Nic prostszego:
User-agent: *
Disallow: /adres-sciezki/A możesz chcesz wyłączyć z blokady jeden plik?
User-agent: *
Disallow: /adres-sciezki/
Allow: /adres-sciezki/nazwa.pliku.formatBlokada konkretnego rozszerzenia plików
User-agent: *
Disallow: /*.exe$/W tym wypadku robot wie, iż jeśli nawet znajdzie jakiś plik .exe w naszym katalogu, nie powinien go indeksować. Możemy też zablokować pojedynczy plik na naszej stronie:
Blokada jednego pliku
User-agent: *
Disallow: /nazwa-zablokowanego-pliku.format/Tutaj wyraźna instrukcja dotycząca wyłącznie pojedynczego pliku, który przechowuje nasz serwer.
Blokada adresów zawierających określony parametr
User-agent: *
Disallow: /*?*Ta komenda przydaje się często w przypadku, gdy mamy na stronę wyszukiwarkę, która tworzy nowe adresy URL z każdym nowym zapytaniem wpisanym do niej – najczęściej podczas wyszukiwania pojawia się właśnie operator „?” w adresie URL.